SQL Server DBA + SQL Programming + Azure SQL Training (Online)
By Daniel AG, #1 Database Trainer in USA!!! (*****)
Course Description
Our Microsoft SQL Server DBA and SQL Programming course (both on-prem and Azure Cloud) is designed to provide a complete learning pathway for anyone seeking to master SQL Server in today’s hybrid data landscape. Whether you are an aspiring database professional starting fresh or an experienced IT specialist looking to upgrade your skills, this course offers the knowledge and hands-on expertise you need. No prior experience is required, making it accessible to beginners, while the depth of topics ensures value for seasoned professionals.
The program begins with a solid foundation in database concepts and SQL programming using Transact-SQL (T-SQL). From there, you will gain practical knowledge in installing and configuring SQL Server, managing day-to-day database administration tasks, and implementing high availability and disaster recovery strategies to ensure business continuity. The course also emphasizes performance monitoring and tuning, equipping you with the skills to maintain stable, secure, and efficient database systems.
As cloud adoption continues to reshape IT, we include a dedicated module on Azure SQL, where you will learn administration techniques unique to Microsoft’s cloud platform. You will also gain hands-on experience with database migration strategies, enabling you to confidently move workloads from on-premises SQL Servers to Azure SQL while maintaining performance and data integrity.
To enhance the quality of learning, every participant receives official Microsoft courseware, including Querying Data with Transact-SQL and Administering Microsoft SQL Server Databases. These materials align with Microsoft’s certification tracks and can serve as valuable references even after the training is completed.
With over a decade of experience training thousands of students across the USA, Canada, and beyond, we are proud to offer high-quality, affordable programs in SQL Server, Azure, AWS, AI, and related technologies. Based in Philadelphia, USA, our training combines structured teaching, real-world case studies, and practical labs to prepare you for real-life database management scenarios in both corporate and cloud environments.
For complete course details, schedules, and registration, please contact Daniel at +1 267 718 1533 (Mobile & Whatsapp).
Course Information
Daniel's Profile - #1 Database Trainer in USA!!!
Daniel brings over 16 years of experience in SQL Server Administration (on-premises and Azure), SQL Programming, business intelligence development (SSAS, SSIS, SSRS, Azure Fabric, Data Factory), data visualization (Power BI), and performance tuning. His cross-industry background gives him a unique perspective on how data design, data architecture, data management, security, and system architecture come together to deliver robust enterprise solutions.
He currently serves as a Data Architect in the healthcare industry near Philadelphia, USA, while also training and mentoring database professionals worldwide. Over the years, he has earned a reputation as one of the most trusted trainers in SQL Server, Azure Fabric, Data Engineering, Power BI, Microsoft AI, and related technologies.
Microsoft recognizes Daniel’s expertise with the following certifications:- Microsoft Certified SQL Server DBA
- Microsoft Certified Azure Solutions Architect Expert
- Microsoft Certified Azure Data Engineer
- Microsoft Certified Trainer (MCT)
- MCSE in Data Management and Analytics
As a trainer, Daniel has mentored more than 3,000 students across the United States, Canada, and globally, helping professionals advance their careers in SQL Server, Azure, AWS, and AI. His teaching style blends real-world project experience with a structured, hands-on approach, making complex concepts easy to understand and immediately applicable.
Connect with Daniel at +1 267 718 1533 (Mobile & Whatsapp)
.Daniel's Technical Blog: https://empiredatasystems.com/blogs

Talk to Daniel
Live Training Videos
We believe in letting our prospective students to watch recorded videos of our live training classes and decide for themselves. If you would still like to attend a one-on-one live demo session, please give call Daniel @ 267 718 1533 and he can schedule one for you at your convenience.

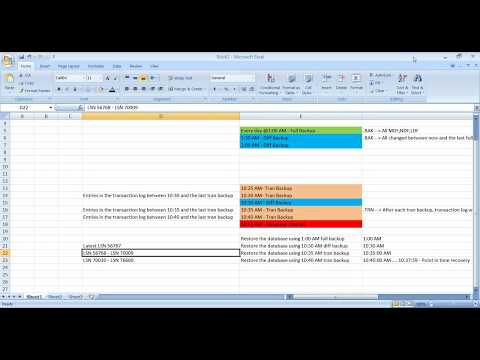
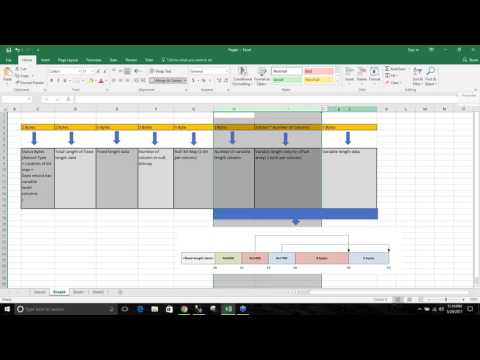
Course Content
Part 1: SQL/TSQL Programming
RDBMS Concept
|
SQL Server Architecture
|
Creating schemas
|
Selecting appropriate data types
|
Adding constraints
|
Implementing various types of joins
|
Joining a table to itself
|
Combining queries with set operators
|
Scalar and Aggregate Functions
|
Summarizing data with aggregate functions
|
Grouping data
|
Extending group queries
|
Building crosstab reports
|
Declaring variables and parameters
|
Calling built-in scalar functions
|
Performing Extensive Analysis with Analytic Functions
|
RANK Function
|
Extending the use of aggregates
|
Building Sub-queries
|
Correlated sub-queries
|
Common table expressions (CTE)
|
PIVOT/UNPIVOT
|
Derived Tables
|
Maintaining Data
|
Transaction
|
SQL Server locking fundamentals
|
Programming procedural statements
|
Handling errors
|
Producing server-side result sets
|
Views
|
Functions
|
Triggers
|
Stored Procedures
|
Temporary Tables
|
Part 2: Database Administration
SQL Server Installation and Features
|
Storage Architecture & data redundancy
|
Essential tools
|
Creating and Managing Databases
|
Managing database space
|
Moving databases
|
Implementing Server and Database Security
|
Authorizing database access
|
Managing Permissions
|
Schemas
|
Catalog Information
|
Handling object-level permissions
|
Creating and managing indexes
|
Creating and managing Statistics
|
Transaction Log
|
System databases
|
Recovering from Disasters
|
Restoring databases
|
Export/Import data/database
|
Automating Tasks with Jobs and Alerts
|
Multistep jobs
|
Performing Database Maintenance
|
Ad hoc monitoring
|
Database Availably
|
SQL Server logs
|
Dead Locks
|
Latest Topics
|
Part 3: Performance Tuning
Executing queries
|
Performance tuning tools
|
Memory Management
|
L-L-W Issues
|
Lock Mode
|
Isolotion Level
|
Lock Granularity and Hierarchies
|
Analyzing performance using
|
Design effective SQL statements
|
Partitioning strategies for tables
|
Indexes tuning
|
Statistics Tuning
|
Part 4: Advanced DBA Topics
Advanced DBA Topics
|
Part 5: Azure SQL Infrastructure (Azure SQL + Managed Instance + Azure VM)
Azure SQL: Portfolio & setup
|
Azure SQL: Networking & access control
|
Azure SQL: Security deep dive
|
Azure SQL: Backup/restore & recovery
|
Azure SQL: HA/DR patterns
|
Azure SQL: Performance architecture & sizing
|
Azure SQL: Query performance & tuning
|
Azure SQL: Monitoring & automation
|
Azure SQL: Migration strategies
|
Azure SQL: DevOps & governance
|
Course Statistics
16
Years of Experience
3671
Gratified Students
112
Training Batches
9634
Training Hours
Gratified Student Feedback - From Year 2000
-
A fantastic instructor delivered a thorough and outstanding lesson in great depth. I heartily suggest it to anyone looking to get started with SQL Server and Azure.
Course: SQL Server DBA/TSQL
Trainer: Daniel
Md Nasir Uddin
Texas, United States -
Just finished Daniel's SQL Server DBA training — honestly, it was really good. Everything from basics to advanced topics like performance tuning and HA/DR was covered in a simple, easy-to-understand way. The hands-on demos and real-world examples made a big difference, and the instructor (Daniel) made sure no question was left unanswered. Definitely recommend this to anyone looking to get into SQL Server DBA or level up their skills.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Arega K. Eniyew
Maryland, United States -
Comprehensive and amazing course taught in detail by a great trainer Definitely recommend to anyone who wants to hit the ground running on sql server and azure
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Muhammad Faizan Khan
Texas, United States -
This SQL Server training is easily one of the best I’ve taken. Daniel is incredibly friendly and made sure everything was set up smoothly even before the training began. The course is fully hands-on, which made a huge difference in understanding real-world DBA tasks. If you're looking to move into a DBA role or sharpen your current skills, this training is absolutely worth it. Its money and time well spend.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Jelili Mustapha
Alberta, Canada -
Excellent course!
Course: SQL Server DBA/TSQL
Trainer: Daniel
Anand Tiwari
Tracy, US -
It was the best SQL Server and Azure SQL course and the trainer
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Yusra alsharif
Euless, US -
Daniel's course was helpful indeed!! Very good course content and excellent course delivery.
Course: SQL Server DBA/TSQL
Trainer: Daniel
Mearg Gidey
Bloomington, US -
The SQL Server course was well-detailed, with a lot of information shared. Coverage of Azure SQL topics was also very helpful.
Course: SQL Server DBA/TSQL
Trainer: Kingsley Onyejide
Kingsley Onyejide
Houston, US -
This course was comprehensive and clearly presented. The ability to revisit class recordings has allowed me to deepen my understanding of the subject matter. Daniel is a great trainer and a subject matter expert in SQL Server.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Sheena A. Jean-Baptiste
Atlanta, US -
Daniel Ag's Comprehensive SQL Server 2022 DBA + SQL Programming Training is an excellent course that blends in-depth database administration with practical SQL programming skills, making it highly suitable for both beginners and intermediate learners. His teaching style is clear, structured, and methodical, with real-world examples that simplify complex concepts like recovery models, indexing strategies, and performance tuning. What stands out is the balance between theory and hands-on exercises, allowing students to not just understand but also practice SQL Server administration and programming in real scenarios. Overall, Daniel's expertise and approachable delivery make this course a valuable investment for anyone aiming to build strong foundation in SQL Server 2022.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Vairavasamy Arumugam
Auburn, US -
I want to thank U for the excellent teaching of SQL SERVER DBA.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
SREENIVASA R. NATLA
Roseville, US -
Great course! The instructor, Daniel AG, is great at explaining concepts and goes in depth of them. Very receptive to any questions and clarifications. Would highly recommend this course.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Shaun Fernandes
College Park, US -
Daniel is really dedicated and thorough instructor! I look forward to taking more of his courses. He is there in real-time answering questions so for someone like me, I am an older learner and it just makes it easier when its live.
Course: SQL Server DBA/TSQL
Trainer: Daniel Ag
Michelle Hinds
Pahrump, US -
Daniel is the best trainer for SQL Server programming. I learned a lot from attending his training session.
Course: SQL Server DBA/TSQL
Trainer: Daniel
Suhashini Saamin
Frederick, US -
I recently completed the SQL Server 2022 DBA/TSQL training led by Daniel AG, and it was an excellent learning experience from start to finish. Daniel’s expertise and real-world knowledge were evident throughout the sessions, making complex topics easy to understand. The course was well-structured, with a perfect balance of theory, hands-on labs, and practical troubleshooting tips. Daniel’s teaching style is engaging, patient, and interactive—he always encouraged questions and took the time to explain concepts in detail. I particularly appreciated the real-world scenarios, best practices, and the extra support offered outside class hours. After this training, I feel much more confident in my DBA skills and T-SQL scripting abilities. I would highly recommend Daniel’s course to anyone looking to build a strong foundation in SQL Server administration and development. Thank you, Daniel, for your dedication and for delivering such high-quality training! — Pankaj Kumar
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Pankaj Kumar
Tallahassee, US -
Thank you Daniel, you have a great course. I will be taking it again so I can get more from it. There was a great deal to learn, and I need to put more effort forward next time. My Best, -Tom
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Thomas Zeler
Rosemount, US -
Great class! Daniel is an exceptionally knowledgeable SQL instructor who guided the class through both theoretical concepts and hands-on exercises with clarity. He effectively connected the training to real-world applications, making the learning experience even more valuable. Thank you, Daniel, for sharing your expertise, insights, and practical instruction.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Christopher Banks
Winchester, US -
I wanted to express my sincere appreciation for your SQL Server DBA/T-SQL course. The teaching style is both engaging and practical, making complex database administration topics approachable and easy to understand. The real-world scenarios you incorporated, along with hands-on labs and clear explanations, have significantly boosted my confidence in both day-to-day DBA tasks and advanced T-SQL concepts. I especially appreciated your patience in answering questions, your depth of technical knowledge, and your ability to connect theory with practical solutions. The course content was well-structured, covering key topics like backups, disaster recovery, performance tuning, and security—each presented with clarity and real-life relevance. Overall, this course has equipped me with essential skills and best practices for managing SQL Server environments efficiently. Thank you for your dedication and support throughout the training. Looking forward to attending more sessions with you in the future!
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
John Jacob
New York City, US -
Danial, thank you for delivering a well-structured and insightful course on SQL, DBA, and T-SQL. Your expertise, clear explanations, and practical teaching approach greatly enhanced my understanding of the subject. The course was highly informative and professionally conducted. Thank you for your valuable guidance and dedication.
Course: SQL Server DBA/TSQL
Trainer: Danial AG
Rubas Zafar
Sahiwal, PK -
The course was great; you could tell Daniel knew what he was discussing.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Helen Solomon
Wilmington, US -
Great course. Daniel is very supportive and a great mentor.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Ade Agabalogun
South Old Bridge, US -
The course was well organized and covered all essential topics very clearly. Examples provided were important and those where one encounters in real work environment. I personally gained the skills and know how relevant for becoming SQL developer and/or MSSql server DBA. Finally, I highly recommend this course for anyone who is interested in learning MS SQL server from the well experienced trainer Daniel AG.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Hailemichael Ganania
Durham, US -
Very interesting class and Professor Daniel makes himself available to help students grasp the concepts.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Donmale Gbaanador
Houston, US -
Amazing and knowledgeable instructor
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Birutawit Burukie
Denver, US -
The course was well-structed and the content was engaging and Daniel did an excellent job of explaining complex concepts in a clear and accessible way.
Course: SQL Server DBA/TSQL
Trainer: Daniel AG
Netsanet Jilcha
Matthews, US